
在测试的时候可以正常成功的获取到分页的数据
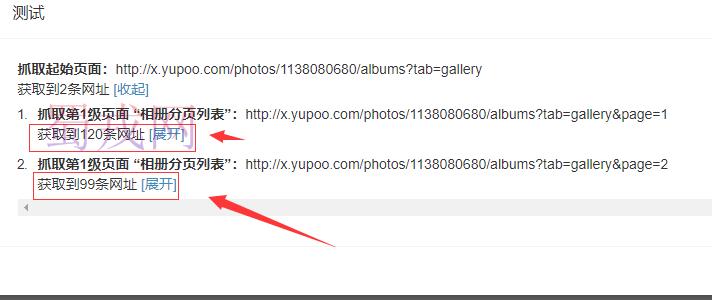 但是在正式执行采集任务的时候则是这样
但是在正式执行采集任务的时候则是这样
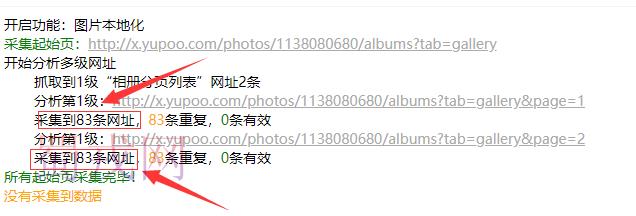
源码中的分页码网址不合规范,“=”导致无法识别

网址规则
感谢,完美解决
但是在正式执行采集任务的时候则是这样
源码中的分页码网址不合规范,“=”导致无法识别
网址规则
- photos/(?<content1>d+?)/albums?page=(?<content2>d+?)
- http://x.yupoo.com/photos/[内容1]/albums?page=[内容2]
admin 发表于 2018-7-20 21:24
网址规则
感谢,完美解决
