
分类信息在网络中的使用率仅次于文章,通常为列表格式数据,所以采集分类信息的流程很简单,可以直接将列表页当做内容页来采集,如果需要从列表页中分析出内容页,那么采集流程就类似于文章采集,本教程重点讲解采集列表形式的数据
前面说了可以直接将列表页当做内容页来采集,那么起始页设置成什么呢?一般可以设为分类链接列表或者关键词搜索链接列表(该教程绕过这步)
以http://shili.skycaiji.com/info.html为例,基本上所有数据都在该列表中,所以无需进入内容页采集,直接将起始页设置为内容页网址

保存后点击测试抓取内容页网址,然后点“分析”进入分析网页界面
列表数据都有一定的格式规律,我们先匹配出每一条数据的包裹层,点击图片元素,然后使用底部控制台中的父元素来调出包裹层
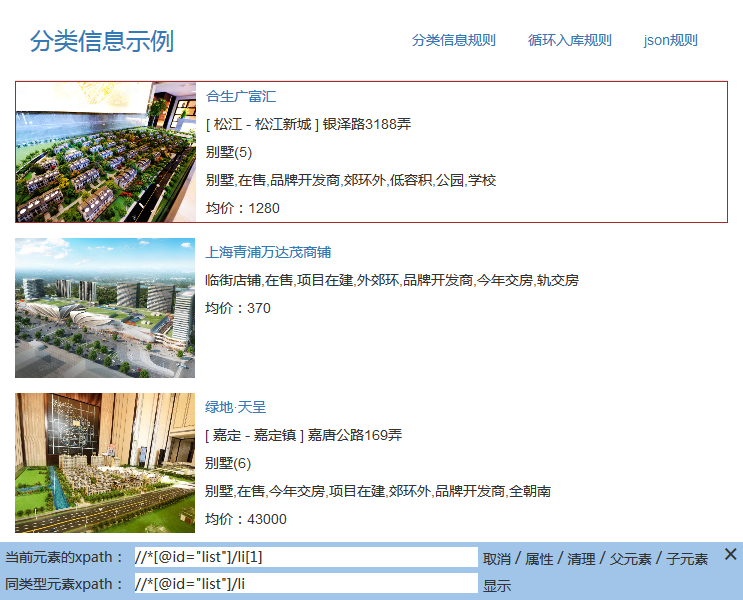
得出第一条数据包裹层xpath://*[@id="list"]/li[1]
同类型包裹层xpath://*[@id="list"]/li
在“获取内容”中添加字段,获取方式选“xpath匹配”,规则输入同类型的xpath,勾选“允许匹配多个元素”并选中“循环入库”
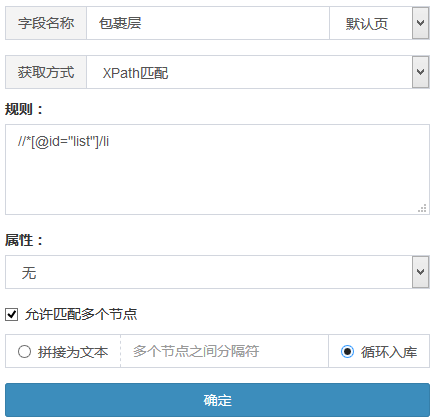
保存测试下看
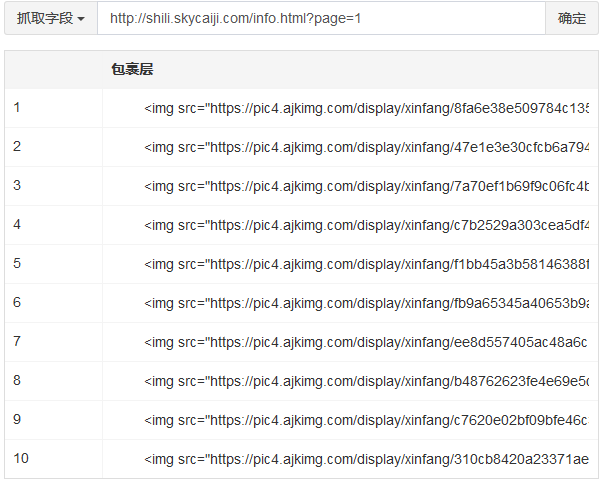
成功抓取到包裹层列表,接下来从每个包裹层中匹配出字段数据
以第一条数据为例,第一条包裹层html源码:
先添加一个图片字段,获取方式选“字段提取内容”,选中“包裹层”字段,提取内容选“xpath匹配”
由于是从包裹层中提取图片,所以图片xpath只需要相对于包裹层就可以了(不用根据整个页面写xpath)
填写图片xpath://img[@class='img'],属性选“src”

保存测试看看
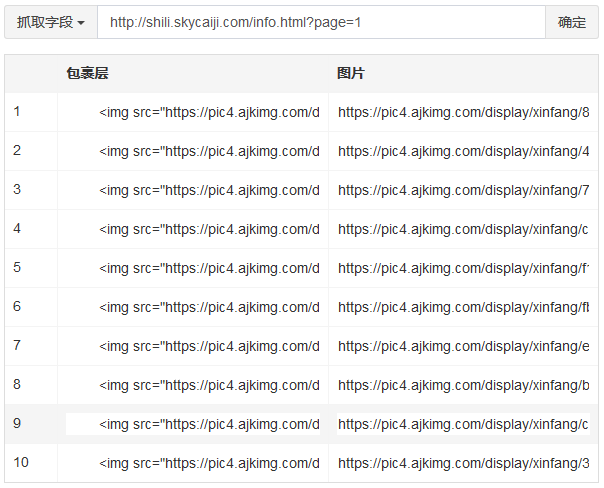
成功从每个包裹层中匹配出了相应的图片链接
接下来再添加几个字段,操作类似于图片:
标题xpath://div[@class='title']
地址xpath://div[@class='address']
户型xpath://div[@class='huxing']
标签xpath://div[@class='tags']
均价xpath://div[@class='price']
注意以上字段xpath匹配的属性选择“text”可直接过滤掉html代码
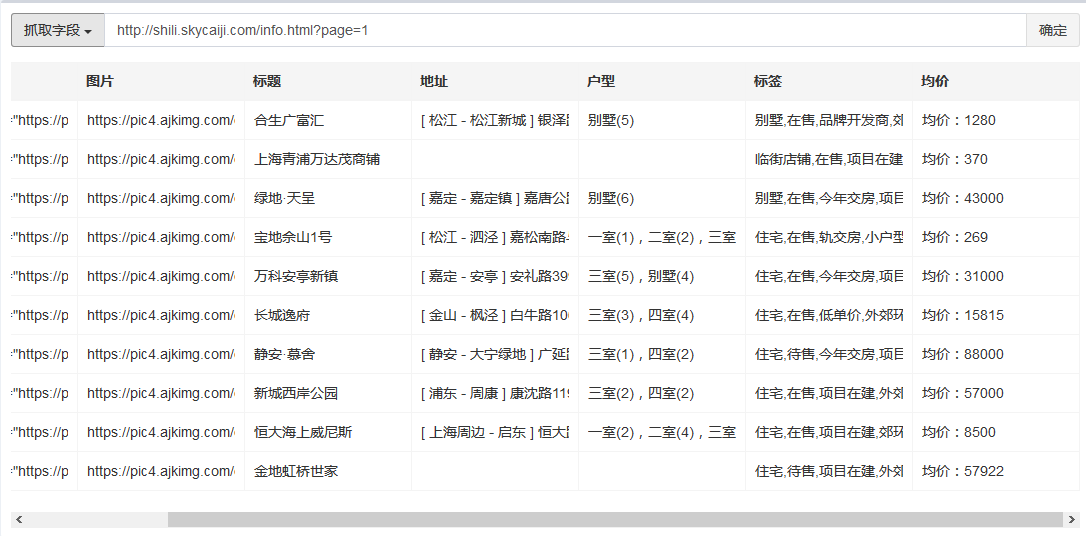
测试结果:
采集列表数据的教程就是这些了,流程很简单,就是编写字段xpath比较繁琐,还有一种不使用包裹层而是直接将每个字段都设置为循环入库(xpath匹配使用同类型元素的xpath)
两种方式都已上传云平台
包裹层:http://www.skycaiji.com/Collect/rule/detail/id/100156
同类型:http://www.skycaiji.com/Collect/rule/detail/id/100111
如有细节方面问题请在本帖内回复!
